In Chemical Process Industries during plant operation, we continuously generate huge volume of Data. The main sources of this data generation are plant control systems (DCS, PLCs, etc.), ERP system, QC/PC labs, Plant operation log books, etc. This data is very useful to understand the performance and correct decision making for plant operation and various business processes. Therefore, in this article we will try to understand the various characteristic of Data. So, in the course of understanding the data, first let us understand why this data is important to us?
Table of Contents
Why Data is Important to Us?
- For the successful organizations data is a common language for all the communications. When we talk based on data, the chances of ambiguity and confusion is minimum and all are on same communication platform.
- This common language makes our objective clear and facilitate the fast & corrects decision making.
- In a process data tells us where is the problem and how big that problem is? Moreover, using data we can identify where are we right now and easily quantify where we want to be in future? In other words, we can say it is data which tells us the problem and after solution it is data only which answers about the implemented solution efficacy.
- In Lean Six Sigma or DMAIC methodology data is the basis and good data collection simplifies the problem-solving efforts.
- Data is like a blood for any process or machine and variation in these data tells us about the performance & health of that process or machine.
So, how many types of data we come across, let us understand in next section.
Types of Data
Broadly, we can divide data in two types as explained below:
Discrete Data
This type of data can take limited number of values like pass/fail, ok/not ok, true/false, win/loss, etc. A discrete process output describes an event. In plant operation we can find these data in the example of a batch reactor output result and can represent in a table as below:
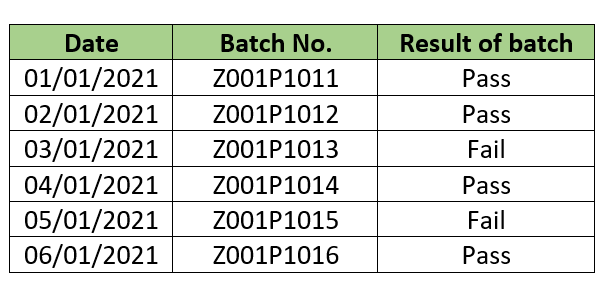
Discrete data provides us the qualitative analysis for the process. Other examples can be processing for NOC application for a new plant – outcome can be either ‘Accepted’ or ‘Rejected’. One more employee satisfaction survey by HR people – results of this is either ‘Yes’ or ‘No’.
Also, we can collect categorical data in orderly form such as, ‘High’, ‘Medium’, ‘Low’. Other form of data collection can be categorical, like data collection for various types of industries in share market – ‘Chemical’, ‘Pharma’, ’FMGC’, ‘Oil & Gas’, ‘Automobile’, ‘Finance & Banking’, etc.
Continuous Data
These are the data for which we require an instrument to measure. We can express these data in either fractions or whole numbers. Like we need a temperature gauge or thermocouple to measure temperature, for pressure we need pressure transmitter or a gauge, flow rate measurement data can be collected using rotameter or an orifice meter.
We can represent these data in form of table and graph, for example steam feed rate in distillation column reboiler:

To understand continuous data characteristics, we need to estimate below parameters:
- Central Tendency of the Data – This we can estimate by calculating mean, median & mode for the given data set. If mean, median is same then we can say our data is uniformly distributed around the mean and symmetrical. In other case when mean ≠ median, then our data will be skewed in shape.
- Dispersion of the Data – To check this we have two parameters first is range and second standard deviation. Higher values of range and standard deviation shows that our data is more dispersed and variation in process is huge. On other side data with lower range and standard deviation values tells our process or machine is running more stable.
Calculation of Mean, Median & Mode
For a given data set we can estimate mean, median & mode to check the central tendency & shape. Below are the relationships to estimate these parameters:
Mean – In a given data set mean is the arithmetic average of all the data points.
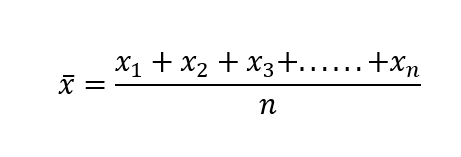
Where n = number of data points
Median – After arranging a data set in the ascending or descending order, the middle data point of the data set is Median. When we have even data points then it will be the average of two middle data points.
Mode – This is a parameter in a data set which tell us about the most frequently occurring data point. For example, if we collect the data for various items sold in a day from a super, the mode of this data set will tell us which item has most demand.
Measuring of Data Spread or Dispersion
To estimate the data dispersion, we can use below parameters:
Range – When we see a data set in this there will be a data point having minimum value and one point will have maximum value. So, the difference between this maximum & minimum data point is Range for that data set. Higher range means process in less stable and has poor control.
Variance / Standard Deviation – Other parameter which measure how each data points are spread around the mean.
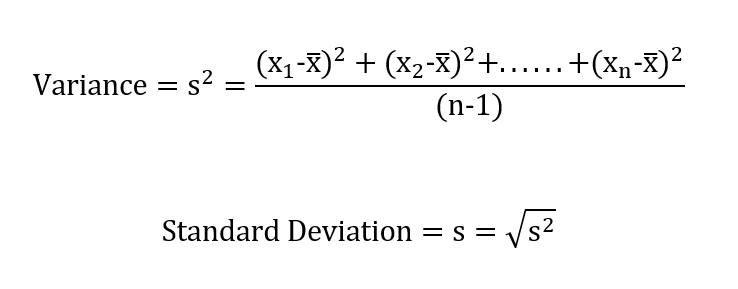
If standard deviation is lower, spread of data will be also lower around the mean and performance of that process in more stable & predictable.
Understanding the Shape of Data Distribution
Based on data points spread around the mean we can classify shape of data distribution in two types as below:
Symmetric Data Set – In this type spread of data points in a given data set is identical around the mean. And, for such data sets mean, median & mode are same.
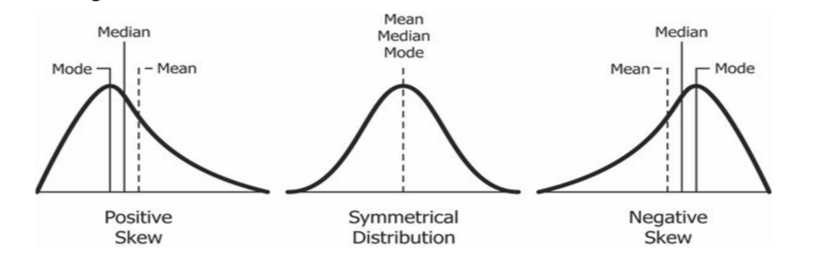
Asymmetric Data Sets – In this type of data sets distribution of data points around the mean is not equal. The distribution will be skewed at either side of the mean as shown in above figure. In case of positive skew mean is lower than the mean and data spread will be high on the right side of the mean. While for negative or left skew, there is high spread of the data points on the left side of the mean.
Performance Baselining Using Data
To start any improvement initiative first we need to collect the data for that parameter of interest or CTQ (Critical to Quality). For example, we can be interested in reactor yield maximizing, distillation column steam norm reduction, batch cycle time minimization, etc. So, for all these cases we need to collect the data for these parameters to see the present performance level. These data will provide us a reference point from where we will measure the process improvement performance. This reference point we call the ‘Baseline’.
For many cases where historical data is not available for our CTQ, in that situation to access the present level performance there we collect data by sampling. Subsequently we calculate the baseline for our improvement project. Let us take an example for reactor yield as below to estimate the baseline:
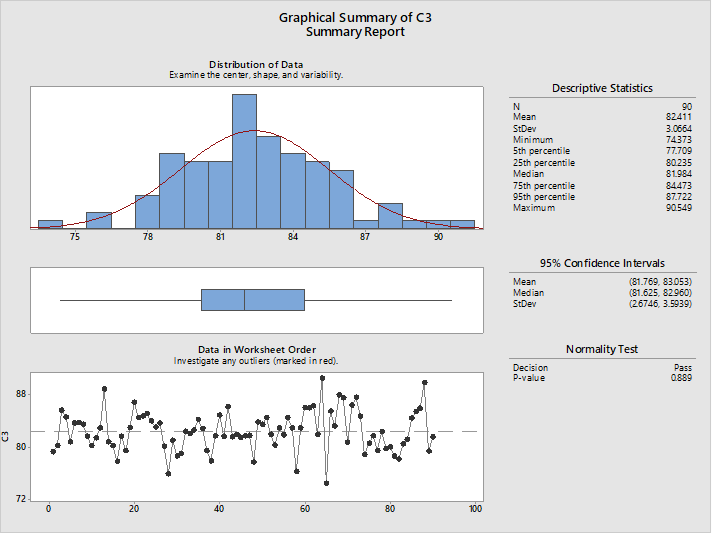
So, from descriptive statics of the reactor yield data set we can find following observations:
Mean is 82.11% and median is 81.98% which are very close to each other. Hence, we can say this process is behaving normally and we can consider Mean (i.e., 82.11%) as a project baseline. This we can confirm by P-value also which is >0.05 for normality pass test.
Conclusion
Finally, we discussed about the need of data, why data is important for us? Then we discussed about the type of data and their characteristics. Also, learned how to estimate various parameters to understand the data set shape and spread of data points. As data is the language of the process therefore, we need to understand the data properly.
At its core data is about making predictions about the process. Using real time data generating from the process, we can develop machine learning algorithms, which can be used to derive AI or artificial intelligence. This artificial intelligence we can use to make timely smart decisions, which in result will provide strategic advantages to the business in terms of higher market shares and better profit margin. Moreover, we can use data with artificial intelligence to make our plant operation safer and more environmentally friendly.
I guess now you can understand how valuable is the data. Using data analytics tools we can get valuable insight about the process. Thanks for reading.